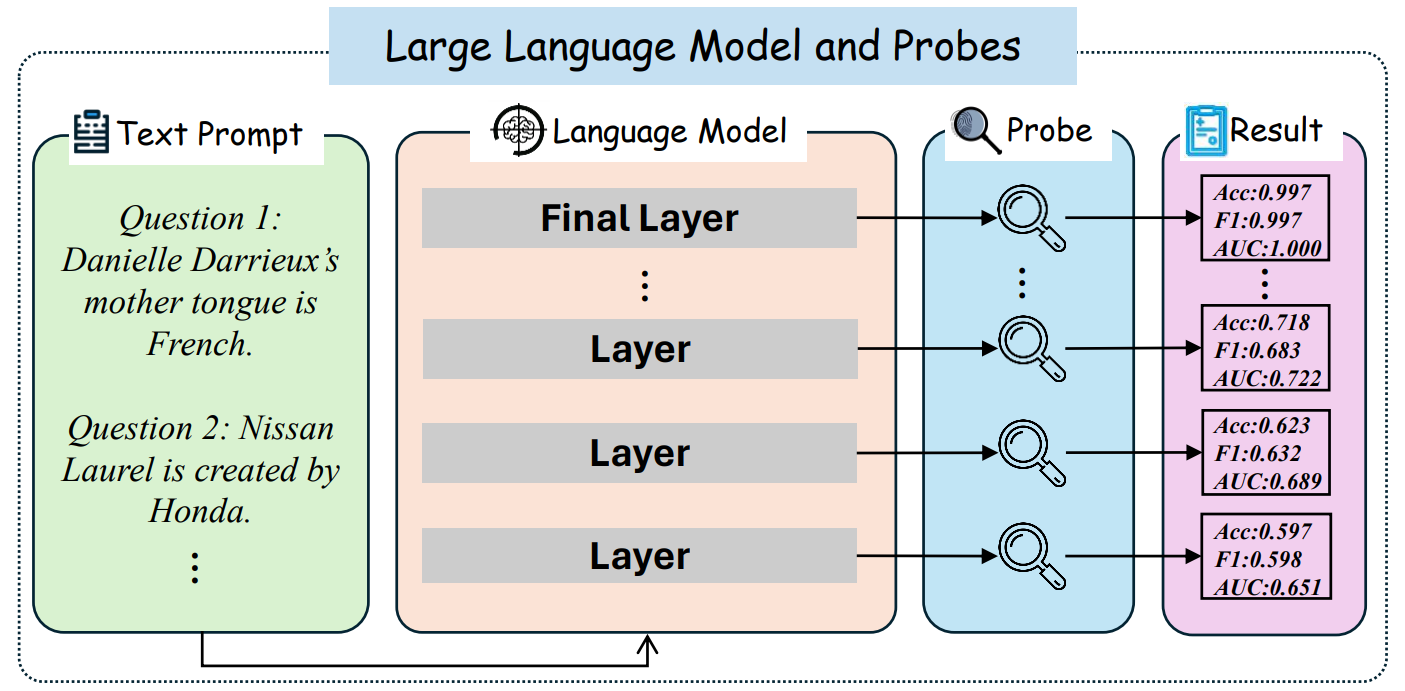
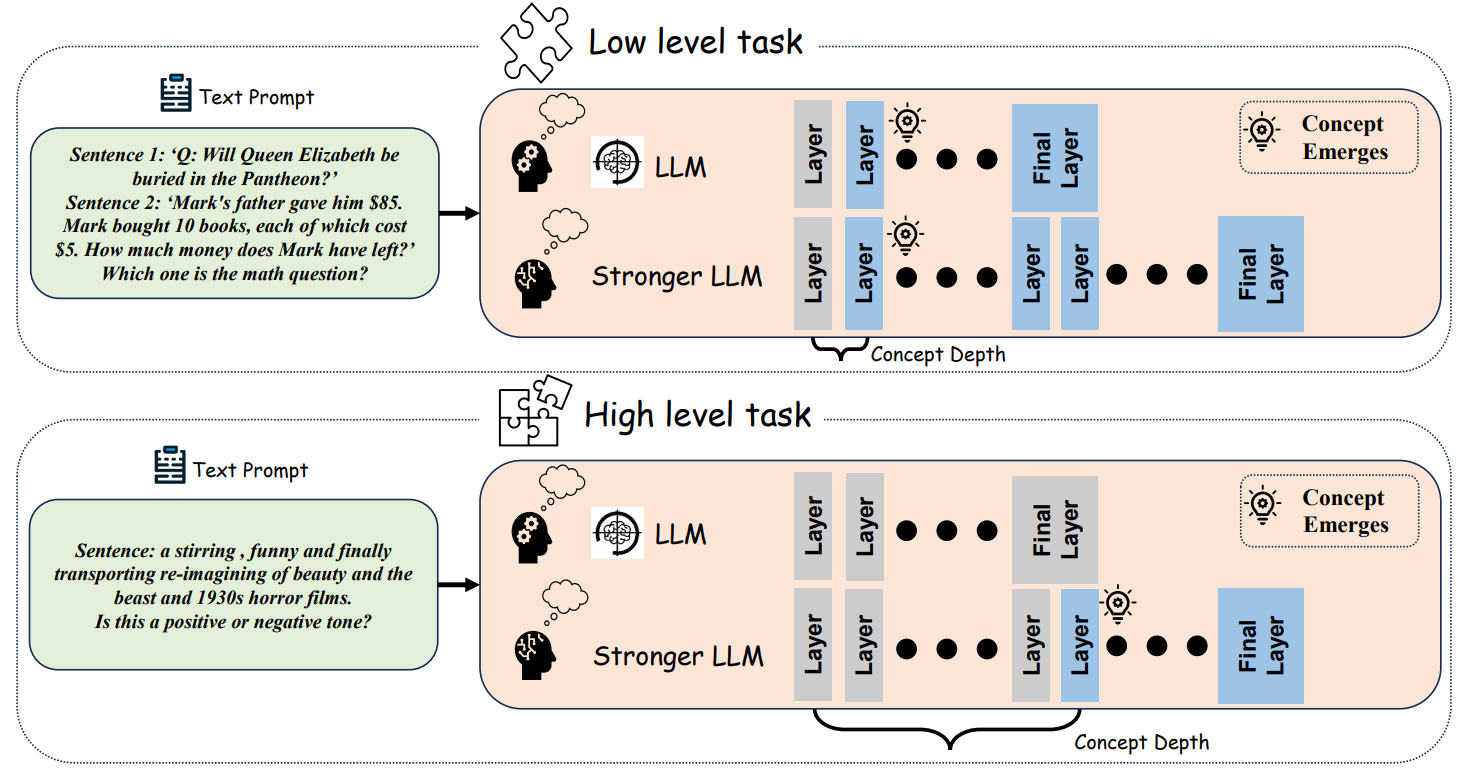
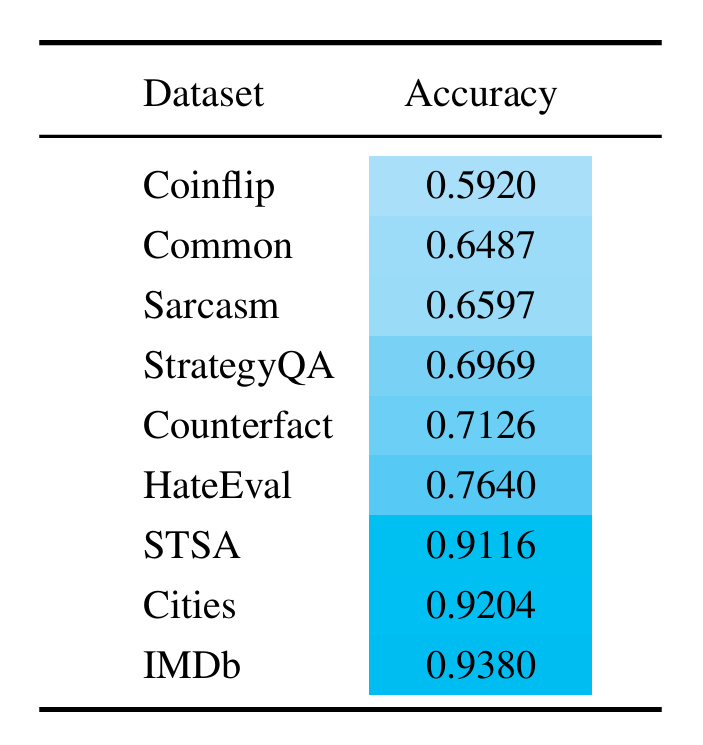
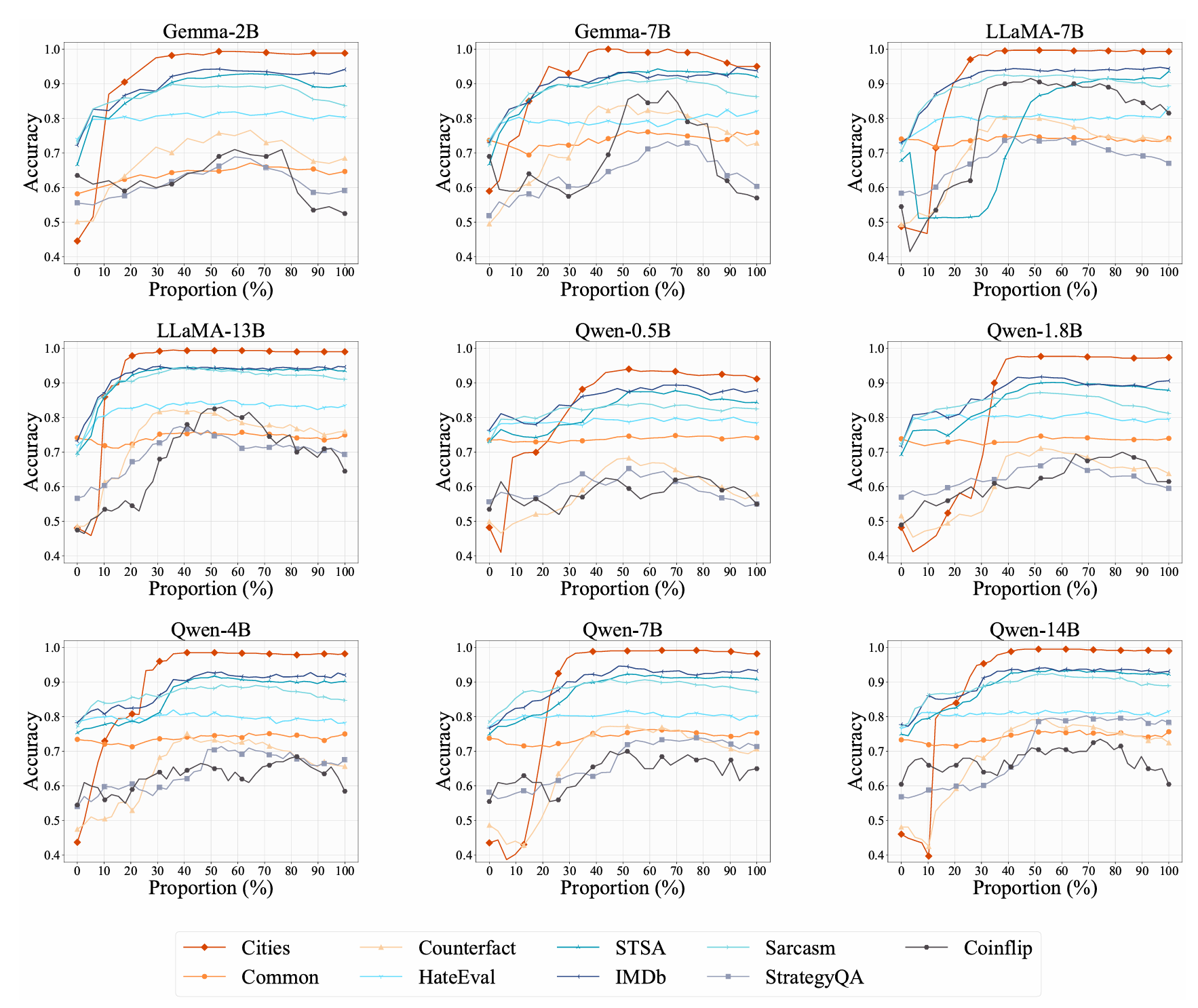
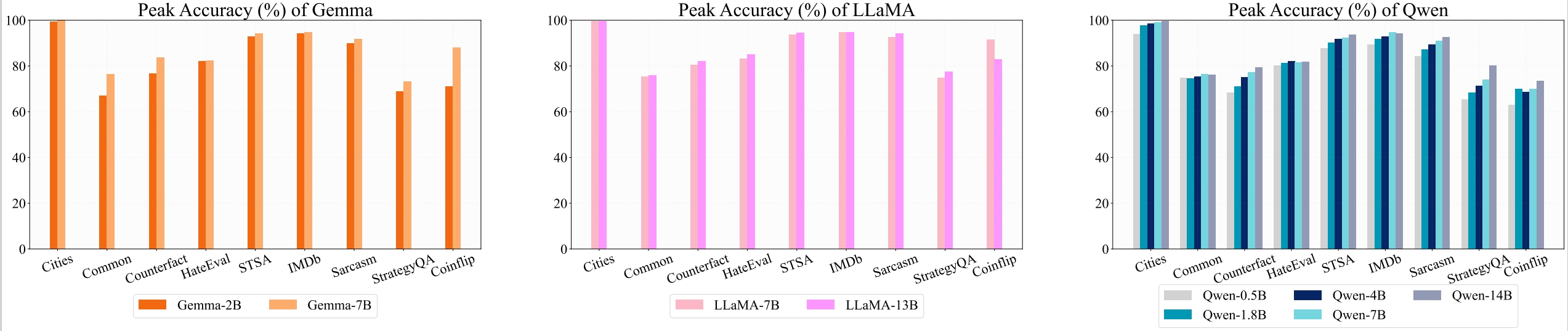
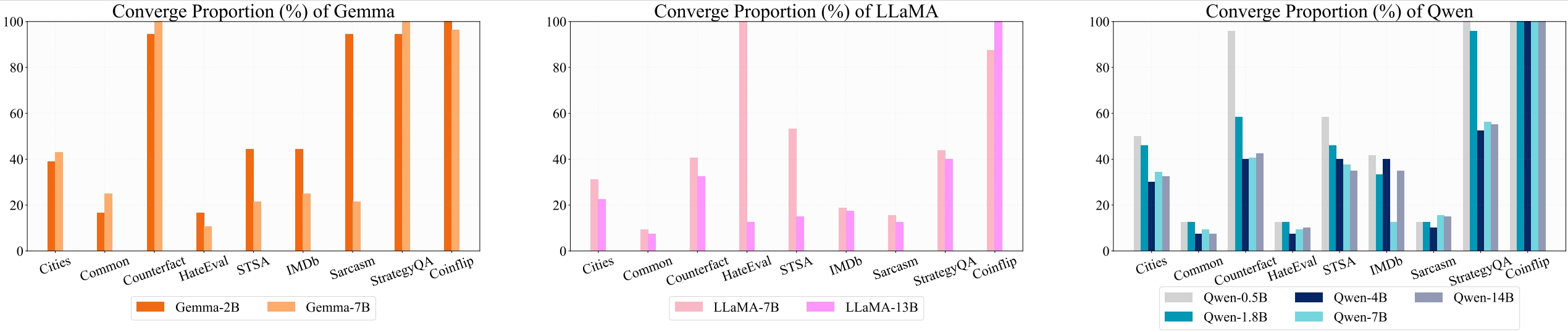
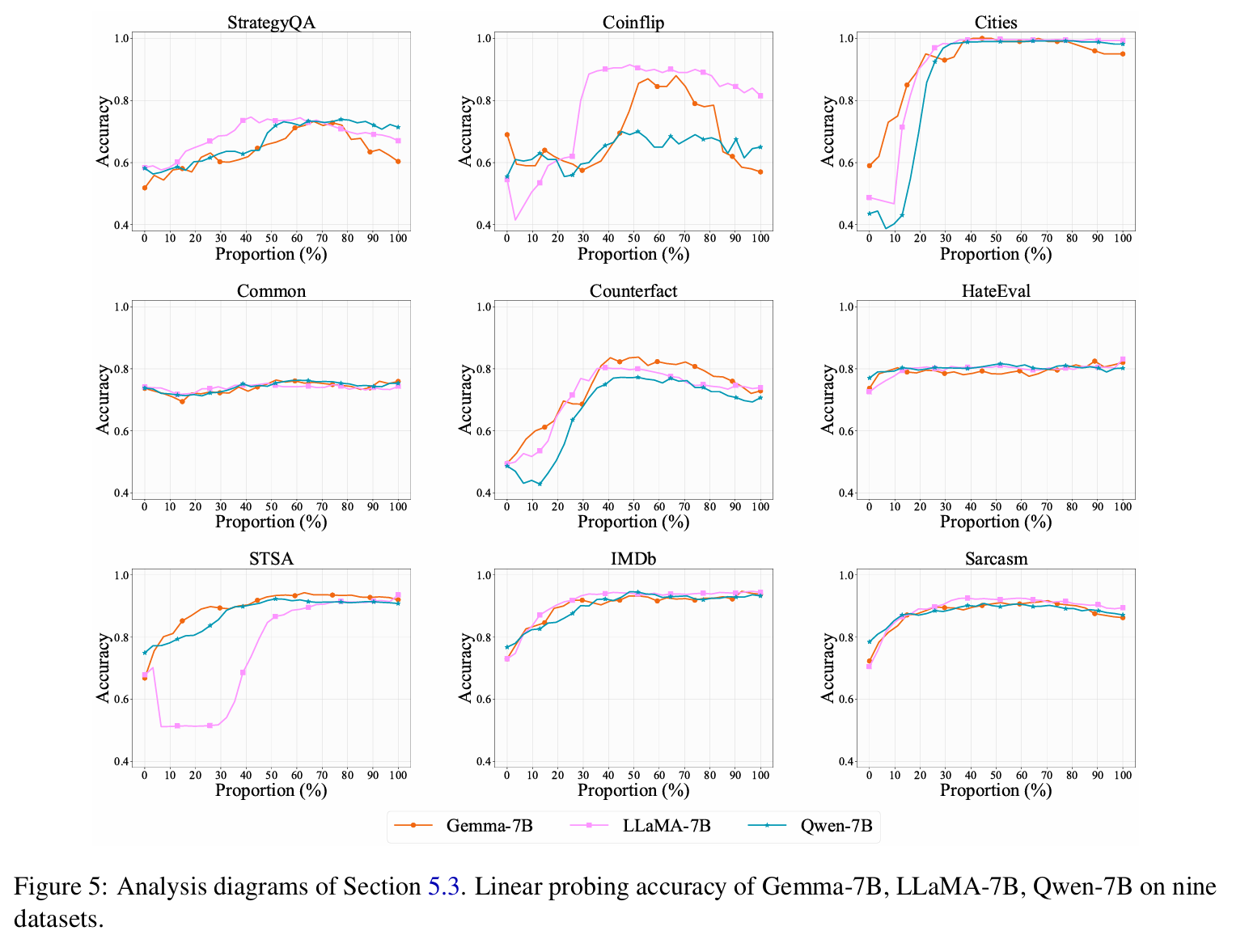
We use the following datasets in our experiments.
💡Fact
We let LLM solve true-of-false problems, based on an objective factual basis.
🌆 Cities: Consists of statements about the location of cities and their veracity labels (e.g., The city of Zagreb is in Japan, which is wrong).
🔎 Common-Claim: A dataset of boolean statements, each labeled by two humans as common-knowledge-true, common-knowledge-false, or neither.
💥 Counterfact: Includes myriad counterfactuals that allows quantitative testing of specificity and generalization when learning a counterfactual.
❤️Emotion
Given a social media or movie review, have the LLM solve a dichotomous sentiment problem.
💢 HateEval: Has tweets which were annotated hierarchically.
🎬 STSA: Includes movie reviews, wih positive and negative reviews, reflecting the writer's overall intention for this review.
📽️ IMDb: A benchmark dataset for binary sentiment classification. We use 2000 of these samples.
🤭 Sarcasm: A superior news headline dataset that tells if the headlines are sarcastic.
🧠Reasoning
Examing LLM's reasoning skills for bi-classification.
🗝️ StrategyQA: Contains questions across all knowledge domains to elicit creative and diverse yes/no questions that require implicit reasoning steps.
🪙 Coinflip: Includes coin flipping queries, asking if a coin remains heads up after it is either flipped or left unflipped by individuals.